You may have noticed I’m posting a lot more lately. It’s partly because I’m not working, plus a bit of conscious effort… plus a couple effort-saving shortcuts I’ve set up.
In the past, I used to share images to Instagram and then had an IFTTT applet run to post those images to WordPress as blog posts. I wanted to flip that model and instead first post to my own site, and THEN have the option of sharing to Instagram or other social networks. The solution I’ve landed on is to use an iOS Shortcut as a Share Sheet action. That means I take a photo, click the Share button, and then click the Post with Pic shortcut.
It's a small thing perhaps, but I do think that making it quick to create a post is an important part of any blogging set-up — and can help with the feeling that blogging is "too hard" or that it's just quicker to use social media. (There was another post I saw recently about why it's good to host your own stuff, but weirdly I can't find it again now.)
I've noticed, thanks to Waymarked Trails, three new walking trails around Fishing Boat Harbour (new to OSM, that is). My first thought was that these are joining up the Americas Cup plaques that are spotted around the place, but I'm not really sure.
So I went for a walk, and found nineteen pink crayfish trail markers.
First up, I stopped at Bill Campbell's bookshop, and bought a copy of A Place of Consequence. He was telling me about when they replaced the floor in that building, twenty years ago, and the fact that there's no cellar there.
My search for the walking trail started at the shipwrecks galleries, where I found a Maritime Heritage Marker:
But then, not far away was the first pink crayfish (or orange lobster, I guess, if we're to follow the tourism guidelines).
After that I had to walk down towards Bathers Beach, but there were no markers to be found at all, and no indication of where to walk. I had to carry on, and around in front of the Fisherman's Coop and over the road before I found a second marker. Then it started to seem that this trail might actually exist (and that I was even following it in the right direction, if the direction of the pink antennae was anything to go by).
The third plaque was in much better condition, because it's mounted vertically on some wooden steps. It pointed to the right along the boardwalk, but the map said that there was meant to be a loop up around Bon Scott's statue. There was no sign of that though. This was the first plaque with a visible QR code, but it resolved to http://11631286 which didn't seem quite right.
After the boardwalk, Little Creatures had a bunch of closely-spaced ones, and then on the other side of the road was the actual main sign board that explained the whole thing.
After that sign things were easy, although oddly one of the markers further along is marked "start/finish" and points across the road. There doesn't seem to be any on the other side of the road, so I guess it was just put in the wrong place. The last marker I could find was back where I started at the maritime museum (I walked past it to start with.
So all up, I think it's definitely a trail, although some fixes are needed in the OSM relation. The map says 12 minutes, but I took 45 (being a dawldling nerd with a camera).
I seem to be giving up (for now) on the idea of a database of photos that I've taken. A while ago it occurred to me that it's silly to keep all photos together just by virtue of the fact that I was the one to click them. Far more useful to sort and store them by usage and proximity to other data.
So I'm experimenting with a document-centric approach, where a wiki page serves as what in other systems might be a tag or album or category. Photos (and other files) can be embedded into that page, and gain their metadata from the page and their place within it. It's looser approach, more like a scrapbook or commonplace book, and I will probably also add at least some per-file metadata (e.g. time and coordinates) at some point. Most of what I want in a record-per-photo system I seem to now be getting from a combination of a calendar view and some manually created lines on a map.
This evening we pulled all of the non-cupboard stuff out of the archive room at the Buffalo Club, and somewhat sorted it. At least, it's organised by size and fragility, and is ready for the next step. It's nice to get a bit of a handle on what's there and what needs to be done.
I'm taking an old frame home to refurbish and see if it can have new glass. Looks pretty solid, in the timber.
I thought today would be a nice day to work from the café courtyard at the Arts Centre. It's cool and shady and the coffee's… well, the coffee's fine, at least (it's not great). But the mosquitoes, they are not fine. They are eating every bit of me, buzzing in my ears, and trying to drown themselves in the coffee. Maybe if they could all drown themselves, that'd be okay. But yeah, shady places with good sprinklers on lawns do perhaps have their downsides.
So TCPKeepAlive enables keepalives handled by the TCP stack implementation (Linux in my case), whereas ServerAliveInterval enables protocol level keep-alives (handled by OpenSSH).
This explains the behavior we’re observing, but also raises new questions:
Can I fix my problem by enabling the ssh protocol-level-keepalives? (ServerAliveInterval)
Why are the TCP keepalives only sent after 2 hours?
Why is my ISP dropping my TCP keepalive packages?
I verified that by setting ServerAliveInterval to 300 (5 min), my problems disappeared. We could stop now that I found a workaround, but let’s keep digging.
I documented my findings, and sent an email to my ISP. I quickly got a response back acknowledging that this is a bug on their side, and thanking me for my research. They still haven’t fixed the problem though.
I am experiencing similar things with my current (new) ISP, SpinTel. Haven't yet had any luck in solving it though. Borg keeps failing after ten minutes or so, and other ssh connections are (almost! but not quite) always failing after some amount of idle time. I've tried setting ServerAliveInterval 10 and ServerAliveCountMax 30 as suggested, but it's no good.
This is an interesting video about the production of Naniwa whetstones in Japan. I can't actually remember what brand I have (the labels have worn off), but they're pretty similar I think. I have some natural stones too, but the artificial ones are good (as far as I can tell!) and are easily flattened with each other (I have two 800s and a 1200 and they're similar enough to work together, and then any one of them is used to do the 5000).
The process of mass producing Japanese abrasive stones. (13:24)
But with Instagram, she says, there’s “no easy alternative” – TikTok “has its own issues” and other platforms with similar reach just aren’t there.
“[For] people who live in the country or in remote areas or minority groups or [who have] small businesses, that is a really good way for them to communicate and reach other people,” she says.
“It’s just not possible to set up an alternative at this point in time. So, to put it bluntly, we’re in a bit of deep shit, to be honest.”
There are old-school photo-sharing platforms including Flickr, Tumblr and Hipstamatic but they don’t have the reach of Instagram.
While social media companies have based their business model on trying to keep users engaged to collect more data and use it to curate advertising, she says, places such as Australia could slow this extraction down with restrictions– such as those in Europe – on how much information they collect.
I guess I'm just not very social, because I don't really understand the whole idea of wanting 'reach'. I like putting stuff on the internet and keeping it organised, and over time it can be seen and used by whoever. I view it a bit like putting a book in a library — I don't feel like it's failed if it's not been borrowed seven hundred times in the first month.
But yeah, I'm not social. I'm not media either.
(PS: And as far as alternatives to Instagram go, I should probably mention Pixelfed! Not that I use it.)
There are a lot of harmful and toxic dynamics to social media that we don’t want to recreate in the indie web… but people do want connection online, and if it feels like there’s no way to connect with others via the indie web, they’ll simply continue to migrate from silo to silo. A little friction can be helpful as a protective measure against harassment and abuse, but right now I suspect there’s too much friction to encourage the types of connection we want more of.
Simple interactions are too hard
Problem statement: simple interactions that are easy on social media, such as likes or short comments like “nice!” or “lol,” are socially awkward / unsuited to use with webmentions
(again, silly) where that RNI is the 'record number' of the item. There is also a 'reference number' that is not present in the URL but which is the far more common ID for these photos because it's often present in the actual scan.
(Books on the other hand have a BRN, and URLs like
There doesn't seem to be any way to link to a record by the reference number, unfortunately. The advanced search doesn't have anything.
So it looks like we'll do best to record both the reference and record numbers, and hope that whatever new database system they're going to move to next will work with one of those.
At 0750, on the morning of 1st March, we landed at East Fremantle boat ramp, rather cold, tired and blistered, but on the whole it had been an interesting and not-too-unpleasant trip.
"Not-too-unpleasant" is about what I remember of sailing on the Swan river as a boy. Not quite enjoyable — although I don't know how much of that was due to the other sea scouts being just so much more capable and confident than me.
Last year, I spent a lot of time iterating on Publish, the publishing interface for my website. This interface is a static HTML page that generates a markdown file. This markdown file can then be published to my website. The Publish page is public, but you cannot publish a blog post unless you have access to my Git repository.
This paradigm works well with my static website. I have a user interface that lets me prepare a post for publishing, and a button I can click that takes me to GitHub where I can publish the page. Having posts in static files and version control is significant to me. Static files are easy for me to reason with. I can see my data without having to use a database.
With that said, I see opportunities to improve the Publish tool that can only be done with a dynamic page.
The main improvement I would like to make is to streamline image publishing.
I've mentioned it before, but the storage and display of images (and other files) are the main things that keep me from switching fully to a static site. I am slowly working on some ideas for making those better, but really I'm not sure it'll ever be fully solved. It's too annoying to have to manually create derivative versions of every file, and (unlike what is described in the above post) I'm not sure I want to add content images to a Git repository.
Being able to drag and drop photos onto a blog post while editing is convenient, but that's not necessarily the workflow I'm aiming for — I generally want to upload things to Commons if possible, and add as much metadata as I can. So there's a certain laboriousness to adding images anyway, and reducing the time at upload mightn't matter too much.
Another challenge to preservation and access is membership organizations that keep their material behind paywalls. They sometimes prevent any of their information from being lent in an online library, which it is their right to do. However while they actively thwart efforts at preservation, it remains unclear whether those groups are adequately preserving their own history.
Some material is preserved intentionally, but a good amount was saved purely by accident. The material we recover and digitize has come from attics and basements, from libraries discarding obsolete material, from long-forgotten FTP sites, from scratched CD-ROMs, and from the estates of people who have passed.
I've been working on cataloguing a bunch of (physical) archival records recently, working through various boxes without really knowing beforehand what is to come. 90% are public, but now and then there are documents that need to be kept private. That's fine, there is a private place to catalogue those — but the system being what it is, the public catalogue is online and the private one is not. Which makes for good security, but it's a split in identifiers and an open question about how to represent the gaps that appear in the public catalogue.
The current way to approach it looks like it'll be duplicating the private identifiers on the public catalogue but not putting in any info about them. Then, all their info gets added to the private catalogue (but vice versa is not done: there's no need to represent all public items in the private catalogue, I guess the idea being that anyone with access to that also has access to the public side).
The goal is that for each long-term storage box it's possible to get an ordered list of what's in it. That list will actually have to be multiple, but it seems like it's all going to work.
The other aspect that's come up is how to add in — sometimes much later on — things like missing pages of documents that have already been accessioned. So far, this has been done pretty sneakily, with them being catalogued (and their scans uploaded to) the older catalogue record, but then the wayward pages being stored in whatever box is currently being appended to. This is not great, as although the entire original document is recorded together (that's nice) it means that there's no record in the per-box list of the missing pages! Not nice.
The fix to that seems to be to create records for each of the separated parts of the document. Then they're just like separate items, albeit ones that have a very close relationship. That feels most solid and just means that each needs to point to the other (and that's something that happens with different items all the time anyway).
So, in summary:
The public catalogue gets 'shadow' items that point to the private catalogue.
Each storage box gets its (multiple) lists of contents.
Any parts of a document that are separate (either in the original order, or where they're now stored) result in multiple catalogue items.
I'm at Good Things café, which I will probably always think of as the Attic. Being here reminds me that there is much more work to be done in documenting Brian Klopper's work around Freo. I've probably posted this before, but there's no point in being a wiki nerd on the internet if you can't get trains into everything:
That's the floor that's below me, as I type this. Bricks supported on what must be quite a number of tonnes of steel.
Anyway, I wasn't planning on working on that bit of Freopedia today; I wanted to get down to the harbour and walk another of DoT's marked trails, the Challenger Cray Trail. What a pun that is, how clever of a government department to try their hand at some word play! No, I'm teasing them. But there is actually an interesting part to the trail, and that the fact that they send people down Molfetta Quays. I'd not thought that it was particularly encouraged for tourists to go there, but I shall take it as license to explore today I think.
After last week's wiki meetup in Ellenbrook I'm feeling rather disappointed in my phone's camera's ability in harsh summer sunlight, and am going to try to keep the aperture small and the ISO down today and probably end up with things that are too dark but which at least have nicer detail.
This morning's walk was a success I think, although I'm growing more disappointed in the Department of Transport's ability to a) put markers where they need to be, and b) use materials that don't degrade to nothing in the sun. Those things don't matter though, because this is really more about ambling around looking at things than it is a necessity to follow the actual trail. I found thirteen trail markers, but only twelve are on this map because two are in the same location.
This is the second of these that I've followed, after the Boardwalks and Brewery Loop a couple of weeks ago. This one goes out to the end of a couple of groynes and so is nicer I think. There's always something totally calming about sitting on the rocks at the water's edge, looking out to sea.
The main sign.
I started at the main sign, but actually it says that the start is in front of Kalis' fish and chip shop, so I headed over there — where there was the lovely sight of a pod of dolphins right in close in the harbour, herding a school of fish up against the wharf. They were being watched by a few excited tourists and some crew on the Marine Rescue boat Resolute. I tried to get a photo of them, but of course that sort of pic never works out (and one should not even try, and just enjoy the moment).
Most of the trail was as boring as expected:
But a few of things stood out:
Firstly this cor-ten obelisk thing.
"
And the seafood factory near it, with it's large flow of water.
The entrance to what was Quest Apartments, but which now has the sillily-punctuated name of "Be. Fremantle".
And the cruising yacht club's 'club house' (such as it is; more masts and less pomposity than the nearby Royal Perth Annex I think).
But most useful, and leading to hopefully another Sunday outing for me, is this map of the America's Cup Walk, which shows the locations of all (or some?) of the competitors in 1987:
I think Pix is my new favourite program. It seems to be a Mint fork of (or heir to?) the gThumb package. Pix seems to have everything I want at the moment, for simple and quick photo fixing.
It will a tough time for pedestrians and cyclists until the new traffic bridge is finished in just under 2 years time – but if you doubt it will be worthwhile, just have a look at the third picture below and couple that with the bridge shuddering every time a vehicle goes past!
And this last pic is just to prove that I was there on the last day.
I’ve been on a bit of a kick lately replacing MySQL (and equivalents) with Postgres. I harbour this dream of only maintaining a single database stack, silly as that sounds.
Normally I’m pretty conservative with what I run, jog, and sit on, but I cloned Clara’s and my other wiki and did a database migration to PostgreSQL over the long weekend, and it… worked? We run MediaWiki stock without extra plugins, but I’m still impressed how there’s been no appreciable difference in functionality or performance. I can now also use my little library of Postgres scripts for backups, and only have one DB on our jailed FreeBSD environment.
I've started the process of moving mwcli off GitHub. There are plenty of reasons for not liking GitHub, but really I'm just keen to keep wiki things together on Wikimedia's GitLab (and Phabricator for issue tracking). I figured it's better to move it before I keep working on improving the tool
I'm trying to figure out how best to bring XML data into Basildon. It's mainly because I want to show Internet Archive items' info and thumbnails, but I'm hoping that it doesn't have to be a IA-specific feature of Basildon.
I started surveying the America's Cup Walk plaques along Mews Road. There are fewer than I'd thought (ten so far), although I've not yet found a source that says how many there were originally (or when they were installed; I'm assuming it wasn't actually 1987, but maybe just a few years later?).
A big thing that keeps me from enjoying Flickr more is the inability to find duplicate files. The API doesn't support any sort of checksum, so for years people have tried to get around it by adding 'machine tags' of the form checksum:md5=1ed002a1483f4ae019470e3c3ffbfc7e. This sort of works, but there's no telling how long the tag search index takes to update — so if you upload a new file, it may or may not appear in search results for days, so any search for it will fail.
Today we added a map to to the Gawler history wiki, using Cargo. So far it's been a good way to find places that have been given quite incorrect coordinates (usually from dodgy address geocoding I think).
While I find computers effective for writing longer prose, hand writing in a notebook affords me more space to think and note. I can stop and notice things around me without wondering what else there is to check on my computer. I can sit still and look around without obligation to write or to write full prose. If I think of something, I can note it down; otherwise, I can, as I wrote in my notebook, let my mind wander.
I made the mistake yesterday of looking at how to determine a user's timezone in MediaWiki. I thought it'd be simple! Of course it's not. It does make sense, mostly, eventually. I'm giving up for now because I have other things to do and because I got to the point of reading the Wikipedia article about time zones and now I don't even know what one of these things is.
Some areas in a time zone may use a different offset for part of the year, typically one hour ahead during spring and summer, a practice known as daylight saving time (DST).
An "area in a time zone"?! That's a different time zone! That's what defines time zones, the fact that they have the same time. Or does it? Time zones all have nice unique names, like "Australia/Perth" where I am now (although note that they don't have nice standard or unique abbreviations — but at least the solid fact that 'EDT' doesn't refer reliably to either Australian Eastern Daylight Time (UTC+11) or Eastern Daylight Time (UTC−4) is actually a comforting piece of knowledge in this sea of confusion).
So they do have names, but what do those names mean? Are they time zones? Is "Australia/Melbourne" a time zone, or is it an umbrella term for AEST (UTC+10) and AEDT (UTC+11)? Are those the actual timezones? And for those, it's perfectly acceptable to define them as offsets (in minutes) from UTC.
And is it "time zone" or "timezone". Hurrumph.
(Which reminds me, I still need to switch my {{post}} template to accept time zone names rather than integer hour offsets, because those are the useful things, when combined with a date…)
So the scaffolding the went up last week seems to be so they can remove the eaves from the southern wall, perhaps in preparation for a new building on the boundary?
The Rogue Scholar science blog archive improves science blogs in important ways, including full-text search, long-term archiving, DOIs and metadata, and communities.
I’ve deliberately left comments turned off for now, as Rodd is working on a project to turn this blog (and RoaldDahlFans) into a static site. This will make the site more secure; it’ll load faster for you; and it’ll be cheaper for me to run. The trade-off is that anything interactive – like comment forms – won’t work anymore. But I know what Emily means, and I miss having that form of interactivity here.
There is an interesting option that I’m toying with – using Bluesky and/or Mastodon for the comments. I’ve seen several static blogs doing this with those networks, and it feels like something I could do. I’ve started doing my research so it may well be appearing here before you know it…
This does sound like a good idea. It makes it possible for people to comment on a post, but not have to register a local account at all. (Like how it'd work if we all used webmentions?) A common approach seems to be to firstly publish the blog post (so that it has a URL), and then post about the post on Mastodon, and then either use the ID of that latter post or a search for the former post's URL (in one's own Mastodon posts) to find the Mastodon post. Once a relevant Mastodon post or posts has been found, retrieve any replies and show them on the blog post.
I might have to give it a go here (although where 'here' will be by the time you read this I don't know, but I think I want to nuke my site and do something different… not that I'm dissatisfied with MediaWiki as a blogging system…).
The other thing I want to use static-site comments for is on genealogy and archives' sites, where it'd be great to be able to get feedback on biographies or catalogue entries etc.
OOUI has a convention where parts of a class file are divided by comments such as /* Methods */ (e.g.). These are not method docblocks (they only have a single asterisk), and the phrases used are: Setup, Events, Static Properties (sometimes spelled with a lowercase 'P'), Static Methods, and Methods. I've not been working with OOUI much in the last year or so, but now am coming back to it, and it's weird but these comments are one thing that stick out to me more than other stuff. There's nothing wrong with them, but they feel like they're in the void that lies between the blocks of code and their docblocks, and it's a surprise to see anything there.
I'm sitting at my new verandah table, with a cup of coffee and the pinging sound of the bridge pile driver in the distance. I like the sound, it's as though an indefatigable giant with good rhythm is bored and banging on the railings. The weather this week is cooler, even cool enough to notice a design flaw in my new table:
The pedestal of the table is cast iron, of large dimensions, which is terrific from the point of view of stability and has the rare feature of not sliding across the floor when you push your feet against it. But it's summer, I'm not wearing shoes, and in resting my feet on the iron I'm getting cold feet.
That screenshot is how the Empire looked between 1900-10-09 when the Cook Islands were added, and 1900-10-19 when Niue was added (not to bowdlerise the act of empire building or anything with a word like 'added').
I've upgraded toolforge:wdlocator to PHP 8.2 and Symfony 7, and in doing so I think have fixed a long-standing (but unknown to me!) bug with how it was selecting the user interface language. It's supposed to change based on the Accept-Language header, but there was a bug with that in our ToolforgeBundle. I think we fixed that bug ages ago, but I forgot to update wdlocator. So now I have, and it can be read in Indonesian at e.g. https://wdlocator.toolforge.org/?uselang=id#map=17/-8.72520/115.17650
(I mention Indonesian, and the map above is centred on Denpasar, because that's where I'm going tomorrow. For the Wikisource Conference.)
I know I should also add a UI for actually selecting a language, but that'll have to wait.
I nerdsniped myself yesterday I guess, and as I've found myself at the airport a bit early (or rather it was quieter than I'd thought it might be and I got through check-in, customs, and security quickly), I'm working on phabricator:T386289.
The modern way (and the old fashioned way; there was a time in between when we thought of it as 'clutter') is to always have a submit button when there's a form input, so I'm going to do that. Something along the lines of this:
Even though that means it takes up two lines instead of one. Perhaps all those things should be hidden in a popup menu of some sort. But that's more work, and the whole sidebar UI of this tool needs an overhaul, so for now I'll just do the bare minimum. Really I want to dig into why the automatic language selection isn't working as expected.
The other thing I've noticed is that there are some languages missing from krinkle/intuition, like Fante. I think I've wondered before about how those are updated, but I can't now remember what the process is. Perhaps that's a nice easy thing to do
An incredibly easy arrival in Bali: I was sitting near the front of the plane so got off quickly, but then getting through immigration look about three minutes. Too quick, as it turned out, because the luggage collection listing had been updated with the wrong info, so I then stood at carousel six for twenty minutes wondering where my bag was — only to find that it was actually carousel three that I should've been at, and where my case was among four others forlornly going around and around on their own.
Sounds like there's amazing work going on in the Philippines around training people (with actual curriculum integration in high schools, if I'm understanding it?) to edit Wikisource —
The first phase comprised the 24-hour basic training course on transcribing, proofreading, and validating of Wikisource pages held from the first week of June toward mid-July 2024. In the second phase, the 40-hour WILMA PH advanced Wikisource workshop commenced with the two-day Bikol Wikisource Training of Trainers (TOT).
Home again now, and trying to figure out what to stick my new stickers on. The {{page break}} one is my favourite, because I use that a lot on ArchivesWiki when transcribing.
Is taking control of your content less convenient? Yeah–of course. That’s how we got in this mess to begin with. It can be a downright pain in the ass. But it’s your pain in the ass. And that’s the point.
And this isn’t just about blogs. This relates to portfolios, code snippets, photos. You name it. What’s made by you should be owned and controlled by you.
Web 2.0 failed. True online sharing died a long time ago. So start taking. Take your ideas, your words, your work–and go home.
I've been sorting out a better workflow for uploading to the Internet Archive. It's only just dawned on me that TIFF files are much better supported than PNGs, and so I'm now going to stick to those (actually I have been for quite a while now, but there are still lots of files that I scanned a few years ago that I'm getting sorted out).
If you upload a TIFF, a smaller JPEG gets derived with the same name (just with `.jpg` instead of `.tiff`). I've not yet looked into what size it aims to generate, but they seem to be about one megabyte.
But the overall workflow needs to me more like:
Scan a few images (e.g. multiple pages of a letter, front and back) and give them meaningful names (spaces and other special characters are allowed, but usually best avoided; the actual item title is given separately).
An item accession number is assigned by looking at the previous highest (actually more normally this is by looking at the count of files in the items/ directory). This is confirmed to be unique and unused by making sure the items/1234.md file doesn't exist yet.
The item file is created, and given a title.
The files are uploaded to IA with a command like this:
$ ia upload ArchiveName1234 -m mediatype:image ~/path/to/scans/ArchiveName1234*.tif
Note that the mediatype doesn't actually have to be supplied, and the item will end up as 'data', but that can't be changed later and so it's best to set it to 'image' (for photos) or 'text' (for letters etc.)
The item file is updated with the ArchiveName1234*.jpg filenames. At the moment this is all a bit manual and there's no system that either confirms that they're correct nor that will make sure that there's a connection between the JPEG and the TIFF; I'll probably improve that at some point.
The IA item is updated with a URL pointing to the item's generated HTML file.
The Internet Archive is only used here for files that can not be uploaded to Wikimedia Commons, because it's much nicer that anyone can help improve the metadata. IA items can be edited only by the uploader, so they're somewhat immutable blobs (Flickr is similar, in this workflow). It does mean that non-commercial and orphan works can be uploaded though, and that's very useful.
Local history wikis often want to have a page for every street. All the streets! Every named road or street or path or laneway or mall. Some people say it's silly because there's nothing to be said about some of them. But that's okay, everything's silly.
First, find all named highways around a point:
[out:json];
wr["highway"]["name"](around:3000,{{center}});
out geom;
I seem to spent lots of tine cutting off tongues and grooves. I quite enjoy it, although not as much as cutting tongues and grooves, that's a very satisfying task.
I'm feeling a bit excited about MediaWiki again at the moment. It's nice. I used to feel this about web software, back in the day — I think in recent years I've somewhat been affected by the latest fads and trends that have been all about static sites and depending on paid services and generally everything JavaScript. But I'm no dedicated follower of fashion, and there's something pretty great about a PHP app with a database, and generating HTML that the browser just displays.
It was WordPress initially, for me, I think. And not long after, MediaWiki, but also Drupal for a good few years, and Piwigo and various other smaller things. All PHP, or at least almost all (UseModWiki doesn't count, although gosh I've just noticed that it's latest version was only a year and a half ago, so maybe I never needed to have moved on from it at all).
(Overheard while writing this, from the scaffolding foreman standing not far from where I'm sitting: "alright boys, it's okay, if you break a tile — now I'm not saying you will, but if you do — then that's fine, don't worry, just tell me and we'll replace it". Seems a bold thing to say to some tired-looking blokes plonking piles of steel poles on a tiled floor.)
But yeah, it seems like it's good to be excited about the things we build. That always feeling like something is old fashioned and not really "the way it should be done" just leads to feeling negative about it — but more importantly, I think it makes it easier to not put in the effort to keep things in order and being consistent with the system as it already is. I think MediaWiki and many other systems have suffered from people thinking that a) something needs to be improved; b) there's a new system for doing that thing; c) we should switch to that new syste; and d) maybe at some point when we feel like it going back over everything and updating it to the new system. It's no great surprise that the last point is the tricky one, and can take years and sometimes never really be finished.
So I'm going to try to stick with paying attention to the details, to consistency, and to working with what we've got (happily).
(The scaffolders are getting closer and will in one more trip be right next to me I think, so I'll run away now. Although they're now getting sidetracked with telling stories of scaffolding in sulphur mines, which is interesting, and they're good at projecting their voices 50m so I don't really feel that I'm eavesdropping.)
The site redesign that we have been working on for a year is almost ready. Since December, the team has been working around the clock to implement the plans we discussed.
Right now, we are finishing up final details, a handful of Project Leaders are testing pages, and leading app developers are working on modifications to Tree Apps and browser extensions.
We are hoping to release the new site on March 10.
The release won't go smoothly. :-) Our community will be disrupted by all the changes. More fundamentally, there will be many problems. Not all our changes will turn out to be improvements. After the release, we will work together to make things better.
I like the "there will be many problems"! It's always true of any big new thing, and it's nice to see it not being coated in corporate-speak.
I'm reading a book from Black Apollo Press, with heavy smooth floppy paper (it's a paperback); almost too glossy. But it's very nice to read. Stays open well enough. The typos are slightly annoying, but they seem to be getting more widely spaced and who knows, maybe the author wanted an element of the rough and ready? (Probably not.)
There's weird cold wet stuff falling from the sky. Perhaps the scaffolders have hit something? Or is summer over?
I'm looking out over Princess May Park (named after the school that was named after the lady who named it), at a long string of about a hundred teenagers hurrumphing their way across in damp hoodies. Where are they coming from ? To where are they going? Are they on day release? Heading to mass? Hard to know.
And in usual Perth fashion, the rain seems to have already stopped.
(I've just noticed the copyright notice on the above radar image. Do they claim copyright on the rain?! )
Copious use of named subqueries (due to them being isolated by the optimizer) can really help here.
If you are fetching distinct terms (or counts of distinct terms) ensuring that blazegraph can use the distinct term optimization is very helpful. It seems like the blazegraph query optimizer isn't very good and often cannot use this optimization even when it should. Making the group by very simple and putting it into a named subquery can help with this.
An interesting post about Structured Data on Commons, and how to query with it. Reminds me that I have been meaning to add support for it to UnlinkedWikibase (although the weird authentication system is perhaps why I haven't bothered so far).
I'm down at Beach Street, because I wanted to take some photos of the bridge progress. But first I'm encaffienating at a caffe. It has a bit of a view, of which I have taken a bad photo.
This non-content post is just me trying more to treat my blog like social media. Share whatever, whenever. No one reads it, so I'm not too worried. But it is useful to keep all things together — as much as I like the ideals of Mastodon, and wikis.world, things like that are still someone else's server and if I've got my own why do I need that?
I have pretty much got all of my piles off books off the floor now and onto their new shelves. My myrtle ones are still in progress, so these Ikea ones (Ivar) will suffice for now (or a few years, or forever…). I do like the adjustability of the shelves, which means that for the first time ever all my woodworking books are together on two shelves (generally, the tall ones have had to be elsewhere).
I've got ten categories: fiction (sub-categories here are still to be determined); reference; general history; Western Australian and family history; Fremantle history; biographies and memoirs; woodworking and tech drawing; travel; philosophy; and technology. And a stack of about half a dozen works that don't seem to fit any category so far.
The first two Buffalo archives' boxes are on their shelf. One is full, one is heading that way. But mainly, we're settling on a system of accessioning and recording, so as that is figured out perhaps we'll get faster at putting things in boxes.
I've just realised that these are probably in reverse order! Oops.
The rebuilt Coles in Fremantle is nearly open. I don't know if it's intentional, but they've put green tiles on the walls that are a slightly similar colour to the ones on the 1970s Target building opposite.
I won't be going to it, but this weekend's meetup at the South Australian Museum sounds like it'll be good:
We’d love for you to join us at the SA Museum for A Wiki Day at SA Museum: From Photos to Facts. We will explore the Wiki Commons workflow - transforming a collection of photos into meaningful contributions across Wikidata, Wikimedia Commons, and Wikipedia. This will be a practical day of discovery and collaboration, working through the full process:
Organising and uploading images to Wikimedia Commons
Structuring and enhancing entries in Wikidata
Using these assets to improve and illustrate Wikipedia articles
I've been helping a bit with the Gawler History wiki lately, which makes me feel slightly more connected to SA goings-on.
There are a couple of buildings wrapped in scaffolding on Victoria Quay at the moment. The first I walked past is the winch shed for the 2000 tonne slipway, with various piles of rotten weather boards lying around, and an intriguing sight through the studs to the machinery and out the other side to HMAS Ovens.
The second building is one whose name I can't remember but I think it's part of the boom defence buildings, certainly it backs on to the smaller brick one of the same. It's all now of course part of Tafe.
Every 20 minutes or so, my phone sends its battery level and charging state to a REST endpoint on my Drupal site. Timing depends on iOS background scheduling, which has a mind of its own.
[…]
It's a little goofy. But that's the fun of having a personal website–you get to make it yours.
This reminds me of my experiments with recording my GPS position automatically on my website. Ultimately I found it less useful than I'd thought it would be, mainly because it's often the times that I most want tracks that the thing failed to maintain a GPS fix. It was fun though, to have everything together in one database.
I don't think I'd bother tracking battery level, but I guess there are other sensors on the phone. Would a database of acceleration events be interesting?
It’s simple, but it hit me just how succinct it is, and how much information it conveys. It’s treating blogging more like a conversation, not unlike an email. I love this.
I think I've said it before, but I do like the blogosphere or indieweb tradition of replying to other people's posts by writing a post of your own. Adding 'Re:' to the post title just makes it even clearer, and looks good in feed readers.
My excitement is cautiously placed. There are undoubtably challenge presents both today and ahead, among them: how do we keep the principles behind the web alive in all generations? Here, “generations” may refer to a period even as much as five years. The web is so new and changing so fast. Trends change.
There is no one answer to the question of keeping the principles behind the web alive, and, more broadly, encouraging more people to start websites. It’s a hard question. But, amid all of this, I cannot help but be encouraged by how many people I have seen start websites.
Everyone should start a website! It's fun. It's as easy as it has been for twenty years, I think, which means either completely complicated and confusing and expensive, or pretty straight-forward and achievable by anyone who understands what a computer file is. Depends on who you ask.
I'm interested at the moment in how web apps (like WordPress or MediaWiki or whatever) are installed, and how easy we make that. It does seem that the "copy a zip file to a server, unzip it, and edit a config file" paradigm is still alive and well and really quite accessible to lots of people. Doing it 'properly' discounts that workflow, I think, and that's a bit of a shame.
Starting May 15, Flickr will restrict downloads of original and large-size images (larger than 1024px) owned by free accounts. If you use a free account, this update applies to both your own content and to content shared by other free members.
We’re addressing the misuse of free accounts as cloud storage for original files—a practice that violates our Terms of Service and negatively impacts the performance and experience for Pro members. By limiting access to original and large-size downloads from free accounts, we can help preserve the integrity of the platform and continue delivering high-quality service to our Pro community.
It's hardly surprising that they're making this change. I do wonder about what dodgy stuff people have been getting up to — is this a matter of tricky steganographic bulk distribution of data in JPEGs?
Anyway, I still like the idea of paying for a service like Flickr. I pay for email, backups, and I think third most important on a list list that would be photos (although of course, I have a complete mess of self-hosted weird photo hosting as well… I just wouldn't recommend that to anyone else, whereas I can reasonably suggest that people use Flickr and the downsides of it are fewer than most other services).
According to the info on OSM (which probably doesn't really belong there) the spot I was sitting was just near the site of a generator building, "due to nature of typical doors and presence of derelict HV cabling and conduit":
Walking past the H2 gun emplacement, I noticed that one of the doors was built by B Makutz & Co. (with a hinge unlike the generator building's):
This side of Oliver Hill has a different heritage conservation policy to the main gun. Here (according to the sign) they aim to "do as much as necessary, but as little as possible", so that we can "gain an understanding of how quickly the army evactuated the Island, leaving a ghostly relic… challenging the visitor to acknowledge the past and the solitude experienced by soldiers". Elsewhere they say that there were up to 9,000 personnel stationed here in WW2, so I'm not quite sure about 'solitude', but I do like the fact that things are left to quietly disintegrate into the sandhills.
After lunch I walked along the spur line back towards where it joined the actual current railway:
Today we went on an OpenStreetMap excursion, for once actually covering some ground. Usually we aim to somewhat completely cover an area, but this time we had one objective: mapping the Bush to Beach Trail, which is part of the Whadjuk Trails network and runs from Shenton Park, through Bold Park, Mount Claremont, and Swanbourne, ending at Cottesloe.
It turns out that if you set up daily warning emails for certificate renewal failures, and then ignore them for a month, the certificate expires. I could've switched to ignoring the UptimeRobot emails that were then sent (of which there would only be two), but because I'm Very Organised I instead fixed the actual problem.
My fifth Wikimedia Hackathon is over, and I think it was the best one yet. It was held at the Renaissance Polat Istanbul Hotel, on the shore of the Marmara Sea on the edge of Istanbul. A great venue, with nice views from the hacking rooms and the dining-room out over the sea with its dozens of cargo ships (and a powership, the likes of which I'd heard of but never seen).
I'm trying now to remember all the conversations I had, about various projects and ideas, and I'm sure I'm forgetting some. Mostly, they were focussed around two main areas: things to do with WikiEditor such as realtime preview and template-inserting; and 3rd party wikis, mostly in relation to local history wikis using Wikidata data, and also how to make wiki upgrades easier for history nerd sysadmins who aren't sysadmins.
My preparation for the hackathon was slightly fraught in parts, with various changes needed to my flights, and even just getting away from Perth started with reports of the terminal being evacuated just before I arrived there. Luckily order was restored and my flight was unaffected, and I got to Istanbul without mishap.
On the flights, and hours of waiting in Dubai, I managed to get started on some hacking projects, mainly T392553 Template discovery: browse templates by category to start with. That's shaping up well, although still needs a fair bit of work and the fundamental idea of it is not really tested yet so I don't know what will happen. I like the idea of being able to browse categories like that, and think it might also be a good additional way to insert categories while editing, but in my testing so far it feels like many categories have too many members for the column-based browsing to feel natural — it works better when categories either have subcategories or templates in them, but not both.
Early on Sunday in the hacking ballroom.
On the first evening and morning (as usual when I travel to Europe, I was dead to the world by 9PM and up raring to go at 4AM) I fixed a thing that's been bothering me for years: T393077 'Preview not loading' error shown when saving a page. So often when I save a page, I would see that error message flash up, and I knew it wasn't actually an error. Thanks to Taavi that's now merged. There is more to do with realtime preview though, and hopefully I'll carry on with the smaller tasks.
One I did want to do was T352504 Remember resized textbox and preview pane sizes, and thanks to MusikAnimal that was the 2nd (and last) of my patches merged during the Hackathon. I think the resizing ability of the edit and preview panes is something that people don't use all that much, and I think having them be sticky will maybe make it more popular. I like having a taller edit textarea for many pages. The sizes are stored in localStorage, so are kept per-device and so will only apply to an individual project and screen size.
A patch that I'd hoped to get merged but didn't was for T335986 Support suggestedvalues in TemplateWizard, but maybe I'll find someone to review that soon. I do want to go over it again though, because the way that TemplateWizard chooses widgets for a given parameter type should match VisualEditor's behaviour. Although, TemplateWizard is a bit more oppinionated in this regard, because it's not constrained by the VE fact of needed to be able to edit every possible value for a parameter (i.e. if you can't enter the value you want via TemplateWizard then you can just do it in wikitext, whereas in VE there's no other way). I think we can get more detailed with TemplateWizard's widgets (although I didn't want to touch the date handling, that's a long-standing discussion without obvious resolution as far as I can remember).
There were quite a few people at the hackathon who work on non-Wikimedia wikis (e.g. schoolwiki.in, fuerthwiki.de) and I had some great conversations about these. There are many wikis that are about topics that are well-represented on (and within scope of) Wikidata, and my UnlinkedWikibase extension seems sometimes useful for these. It needs to be better though, with things like caching, and also have better documentation. To help wikis get started, a couple of us thought it might be nice for it to come with an 'automatic infobox' sort of thing, so in a fit of coffee-powered enthusiasm I got started on T393298 Add generic infobox to UnlinkedWikibase. It may be more work than I thought, but I'll try to get it sorted in the next week or so.
One of the last things I tinkered with was a non-wiki bit of code to bring nicer typography to my Basildon static site generator: #12 Make compatible with the smart-punctuation extension. This is part of an experiment I've been doing into static HTML sites for small archives powered by Commons and Wikidata, e.g. cfbarker.archives.org.au/items/9. I'm not yet sure if this is going to go anywhere, because there are lots of benefits to an actual wiki, such as immediate editing, especially with VE, and being able to upload files that are not suitable for Commons. There's something very appealing about the simplicity and long-term stability of static sites though.
Anyway, all up it was a great weekend, and I'm again in awe of the many people who make these weekends possible. I spend most of my coding life on my own, not talking to all that many people, and so to be able to come together every year like this is very special, and more and more it feels like a really great way to progress things in good ways.
Photos
I'll get more photos uploaded to Commons soon. Most Wikimedia events are well-photographed by people with a better eye than me, so I don't worry too much any more about capturing anything beyond just what catches my eye. Some are useful additions to the general record of the weekend, but most are just visual notes for me.
I've been doing a bit more today in locking parts of Freopedia against annoyingly persistent bots. This isn't a new topic, but these days it's getting silly with the increase from the bastard AI scrapers. A new page, handling web crawlers, has been set up to collect details about how to detail with them, but I thought I'd record my notes here for my own reference later.
I started by fixing up Apache's default log format, to give it some tab characters for easier cutting:
The log format has lots of variables available, the ones here are as follows:
%h Remote IP address.
%t Date and time.
%v ServerName (as defined in the relevant VirtualHost section).
%U URL path (with a leading /).
%q Query string (with a leading ?). (The server name, path, and query string are separated for easier analysis if needed.)
%>s The final HTTP status code.
\"%{Referer}i\" The Referer header.
\"%{User-agent}i\" The User-agent header.
sec:%T Number of seconds taken to serve the request (with a prefix to remind me of what it is).
Then I want to block non-logged in users from accessing a couple of expensive special pages. This could be done with the new CrawlerProtection extension, but that's not compatible with the latest MediaWiki yet so I'm doing it in Apache for now (which is probably more efficient anyway, although it does mean a worse-looking 403 error page):
This looks for a cookie named <wiki-ID>UserID, which is set when a user is logged in. The query string check isn't very robust (it blocks other pages with those strings) but that's fine for now. I might try to improve this at some point (e.g. add history and diffs to the prohibition) and add it to the above page.
The Cargo drilldown page seems to be a bit of a magnet for scrapers, I guess because it has lots of links and if you follow these then you can execute all sorts of possibly slow queries. This can be locked down with a user right:
There's more to be done, but for now removing access to RecentChangesLinked and WhatLinksHere has had the biggest effect on my uptime, and I've postponed once again the day when I have to abandon MediaWiki in favour of a hard to edit but blisteringly fast static HTML site.
These changes seem to be improving things somewhat (note the slight decrease towards the end of 23 May):
Still do to is to prevent arbitrary sizes being created for image thumbmails.
Is this the old Fremantle weather station? It's in the council depot on Knutsford Street. The BOM says that the Fremantle station (site number 9017, which ran from 1852 to 1992) was at -32.0550° 115.7500° (see box on the map below). That's down near the old courthouse in Henderson Street, so I guess it probably was moved around over the years.
Am heading to the Buff for an archiving meeting, and noticed that there doesn't seem to be a photo of Q66974962 yet, so I took one. Perhaps should've waited for better lighting and fewer cars but oh well.
A few weeks ago, I started looking into getting a Casio watch to replace my Apple Watch SE (2024). On Monday, I finally bit the bullet and used a £15 Amazon gift card (I got for Christmas from a colleague at work) to buy one. I looked at a whole load of different ones but I eventually settled on the Casio F-91W. A nice, small, simple digital watch that tells the time.
My watch arrived on Thursday and I got it setup in less than 10 minutes and fell in love at first site. It was really rather simple. Below is a picture I took of my watch once I had it all setup (slightly edited to remove my arm/wrist from the picture as I am quite a private person alien).
It's nice that the F-91W hasn't changed, and that people still blog about buying one. I did so in 2007.
Not that I particularly expect the skin to be of much interest to anyone else, bow that there's clarity around the future of Gerrit (i.e. that both Gerrit and GitLab will remain as Wikimedia hosting options, and that all MediaWiki things should probably go in the former), it feels neater to move everything I can off GitHub.
The other big reason is the spectre of AI rubbish (and by rubbish I mean "features") that Microsoft seem keen to force on everyone on GitHub. I do imagine that at least for quite a while yet it'll be possible to ignore those, but like all these commercial things they'll do whatever makes them the most money. Which is fine — but I'd rather not contribute to the popular idea that GitHub is some altruistic and permanent place of cultural storage. There are enough other options, community-driven and supported by the people that use them.
I went for a walk up the hill this morning, to see how things were shaping up for the "storm". They weren't of course, the BOM just wants to make us think there's going to be bad weather so we have a good old worry and wonder if our gutters are up to it.
Later we moved to a station on the edge of the "open country" as the unfenced land was known, and here Mother's problems became legion. We were the last station on the mail run, and how we came to welcome Bob Brooker and his old, battered, hoodless car, bringing us the mails, the butter done up in a billycan sewn in hessian and dipped in water occasionally, and all the gossip of the district. Our stores came by wagon twice a year, a wildly exciting event. Once it was the legendary Treacle Dick with his camel team, but the rest of the time it was in a wagon drawn by donkeys, with the spare animals and the foals trailing after.
She also mentions a few of the ships that were plying the coastal route at that time, including the SS Mindaroo. So I went looking, and uploaded a couple of photos of it to Commons:
Yesterday I installed Vivaldi in preparation for getting even more annoyed at Firefox (thanks to some piece of unsourced accusatory AI guff about how they were going to get rid of buttons or something… don't worry, I realised it was silly fairly quickly).
But today I find myself going round the twist about some change to how backspace is handled. Has it changed? I thought perhaps I'd knocked some mysterious key combination on my stupid gaming keyboard that had enabled the alt-lock-but-only-sometimes feature, but actually it's just Firefox's browser.backspace_action feature — which hasn't changed for years and my local setting of it also hadn't changed, so I've no idea what's going on.
But anyway, I've turned it off (or on, I guess, as the value is now 1), and can happily type again when my cursor isn't actually focused anywhere. Which, judging by the number of times I was navigating back away from pages, must be quite often. I never knew (and I'm glad it's not Firefox's fault).
I was experimenting with updating the grid layout on the homepage of ArchivesWiki this morning over breakfast:
I keep thinking I'll find time to actually build a skin specific to that site, with some system of each archive collection (i.e. as defined by the presence of a particular template on a page) having its own top-level navigation, and the rest of the site navigation taking second place somehow. As JarrahTree would've said, when I get a round tuit I'll do it.
Firefox has this new feature where it maintains the search terms in the address bar even after you've navigated away from the search engine. I read about it in the release notes, but can't now remember what they're calling it, so I don't know how to turn it off. It's not really what I want in the address bar.
I thought it was going to be raining today, but it's actually lovely. So I'm mapping a missing bus stop, while waiting for a llbus that's not on time. Four 000 buses have gone past. But not mine.
I'm experimenting with trying to speed up the digitisation process of a box of letters. The idea is to photograph sets of 2-5 letters at once and recording them together in a single catalogue item. It makes things slightly more annoying later perhaps, but it definitely makes things faster now.
I'm enjoying Ye Olde Blogroll (blogroll.org), it gives me a fairly constant feed (almost too much at the moment) of people's websites that might be interesting to follow (as in, each feed item is a website; it's not aggregating those sites' feeds). There seems to be all sorts of topics.
One annoying thing about it, or on my use of it in FreshRSS, is that I can't quickly jump to the Ye Olde list, but only to the site itself. Actually, come to think of it, that's definitely FreshRSS's issue: it never provides a quick link to a subscribed site's homepage.
The recent events in the US have made me seriously re-evaluate the idea of using US-based services for web hosting, social media, streaming, and all that jazz. I’m deeply saddened by the state of things, but it is what it is. I know there are a lot of good folks out there in the US (hopefully the majority) fighting the good fight. But in the end, the way things have progressed is forcing my hand to take some drastic measures.
I’ve been moving things to European services where I can, but the reality is that—especially in the web space—most of the best services are based in the US. Replacing them is really hard. At this point, it’s impossible to replace all of them. And I feel torn about having to reconsider even those services that I believe have responsible ownership.
I'm definitely trying to figure out how to shift a couple of things I'm hosting with US companies. The trouble is things like Digital Ocean, who are a US company but who offer cheap hosting on servers in Australia. Most Australian-owned similar services cost lots more (I guess because they're much smaller).
Whether a formal one or not, formal co-ops can be expensive to set up, people helping each other is a nice way to do things. Running a mail and file server for yourself, or for 50 people is a lot less than 50x the work. It isn’t even 50x the infrastructure costs. A fediverse server may buck this trend, as moderation work probably advances faster than linearly with user count. Tensions between local and remote users scales linearly, while tensions between local users scales more like n^2 (at small values of n) as there are more local interpersonal dynamics that can spawn drama. Those are in contrast to a single user instance where essentially all of those dramas are 0.
So a couple of IT adepts doing the IT side of things, a few willing tributes to moderate the fediverse server, and you have a co-op that could see to the prime Internet service needs of a small community.
Another great advantage to this approach is that there's more redundancy with three "IT adepts" running things (than there is with solo self-hosting).
Reminds me of how we used to do co-operista.com, c.2006.
Thanks to a recent wish I've been poking a bit at the InputBox extension lately, to make it work better with MediaSearch and CirrusSearch. This involves making it honour the user preference for Special:Search or Special:MediaSearch (if the extension for the latter is installed), and fixing up the way in which it passes its searchfilter parameter to the search page.
The fix for the first issue was to set the initial form action (which ends up in the parser cache and so can't be user-specific) to the site's default, and then have a front-end switch that dynamically changes it to whatever the current user has as their preference. Slightly clunkily, this involves sending both possible URLs to the front end and then choosing between them, because otherwise they wouldn't be localised.
The second issue came about because InputBox submits search and searchfilter values as separate GET parameters, and then on loading the special page it would changes the internal request object to have a unified value (i.e. these two values concatenated with a space between them). The trouble with that was that you'd end up at a URL like Special:Search?search=foo&searchfilter=insource:Bar and so anything that was accessing the search value directly would get it wrong. So the fix was to unify the values and then redirect to a new URL without searchfilter, and also to skip that redirect by doing the same sort of replacement in the front-end. So most people will not get the redirect, but we always aim to have a no-JS fallback. I did wonder about switching the input names around so that there's no visible change to the text input, which might be confusing to people who see it change but only after they've clicked submit and so there's no time to notice what it's doing.
I think there are similar improvements that could be made to other parts of InputBox, such as type=move with a prefix, but no one's complained about that not working so I don't think I'll bother digging any further for now.
We went to see Mark Tweedie's exhibition at Art Collective WA's gallery, because three of the works are based on photographs from our family's archives:
I'm on holidays this week, which is quite nice.
It's cold today (by Perth standards anyway),
so I'm hiding in a warm café in Claremont before I head out for a walk.
Monday mornings around here seem to be the domain of white-haired well-dressed people with time to idle.
It is raining, but only slightly and it does stop pretty often.
I think I've got an idea about fixing the file upload process in PageForms,
but there's are also lots of other ideas swirling around about what the next steps should be with improving Freopedia.
The upload stuff feels useful because I've sat with a few people recently, showing them how to upload multiple files at once (using MsUpload) and they get a bit confused with what to do after inserting a gallery. So a PageForms multiple-insertion template could work better, as it gives a separate 'caption' field alongside a file-upload field, as well as drag-to-reorder which is pretty nice.
It's a rainy morning in Freo, but the sun is still shining a little bit, and the darkish sky and everything being a bit wet makes for nice colours when the sun does peek through.
I walked the eastern part of the Wardun Beelier Bidi], from North Fremantle to Cottesloe. It was a pretty rainy day, but apart form two moments of actual downpouring I didn't get too wet.
The walk started on Stirling Highway, where there's fairly dismal pedestrian infrastructure.
But once getting to the trail itself things did improve. It comes over the railway on the footbridge, and heads up past the old Tube Makers site (which has recently been levelled, leaving the northern side of the office block exposed).
Then it was up Buckland Hill, past the Leighton Battery, and through some fairly dull strips of scrub that have been left between areas of housing.
I've been getting sidetracked with sorting out some more papers relating to Aubrey Hall, transcribing probably more than is useful. It's good to not do much transcribing while digitising, I think, because it slows things down — but also, reading and transcribing and linking and whatnot is the stuff that I find most interesting, and it gives me enthusiasm to carry on with scanning.
It's also not good to stay inside on a lovely sunny day, so I headed to Victora Quay to check out Freocast's celebration (which was not underway, as it turned out).
There's a bit of a feeling in the air this week that GitHub is no longer the place to be. It's been owned by Microsoft (boo hiss) for a few years, and nothing particular dreadful has happened so far. But now the CEO has left, and is being replaced by an AI cyborg (no no, I jest), so a degradation of grooviness is possibly on the horizon.
I've been casually moving things off GitHub for a couple of years, but not in any comprehensive way. I'm trying to move Wikimedia things to gitlab.wikimedia.org, other things to Codeberg.org, and a few things that are just for me are heading back to being a bare repo in my homedir on one of the servers I've got (it feels like it's 2009 again!). So I guess I'll carry on with all that.
In general, it does feel nice to not be forever consolidating on centralised commercial systems. I do wonder sometimes if Wikimedia sites aren't also overly centralised, but at least they're community driven (well, not "at least" but more "utterly crucially").
I've been reading a bit about the turtle soup factory at Cossack. It's surprising how many similar turtle factories (abattoirs?) there were all over Australia.
This is Myrtle the turtle, outside the backpackers' at Cossack, which I assume was created with recognition of the history of the place:
Some drongo at the UK's Environment Agency (i.e. their Director of Water, which I guess is like being a tap) has suggested that it's the little things that count.
Simple, everyday choices – such as turning off a tap or deleting old emails – also really helps the collective effort to reduce demand and help preserve the health of our rivers and wildlife.
Delete old emails and pictures as data centres require vast amounts of water to cool their systems.
It's not the little things, in this case. Or, maybe it is, but before destroying our collective cultural memory you could perhaps try not using AI for every little thing, or moving your thermostat a degree or two.
It projects that electricity demand from data centres worldwide is set to more than double by 2030 to around 945 terawatt-hours (TWh), slightly more than the entire electricity consumption of Japan today. AI will be the most significant driver of this increase, with electricity demand from AI-optimised data centres projected to more than quadruple by 2030.
Take more photos! Keep them! Describe them well and explain why you took them. Make them available to your community. Those are useful things to do, that are worth spending electricity on (and it's really not very much electricity, in most cases).
For the last 20 or so years we have moved away from paying for the virtual things we use and towards "free" software and services. We stopped paying with our wallets and started paying with our attention and our data. This should not be news to anyone. It needs to stop. We need to get back in the habit of paying for the software and the services that we use.
Today we were moved into the lodge room at the Buffalo Club, to work on the archives. There was a exceptionally loud all-ages gig happening in the main area where we normally set up tables.
Looking out (past broken sash cords) at Hooper's building.
Everything's Buffalo.
Edwin Workman, 1931
No grog allowed upstairs while the gig was on, but we did manage to go below for a beer later in the afternoon.
There was a problem with flash media, though: you generally had to plug it in in the back of your PC (or you'd be smart and get a USB-A extension cable), and they tended to be quite bulky, having large plastic or rubberized cases/bodies. PCs soon adapted with front-facing USB ports, but there was one thing I still missed: having an eject button (or software command)! The thumb drives hung out the front of your PC and could get damaged if you were walking by your PC without thinking and whacked it with your knee.
Still, they were very convenient, and I carried one with my keys for several years, but they never really became the floppy disk replacement. Close, but no cigar.
The funny thing is that we do have a standard removable storage format today! It has plenty of capacity, has a standard size, fits inside your computer (not hanging out the front), is cheap, and almost every computer has a port for it! It's the microSD card! I know, you'll try to curb your enthusiasm. What are we supposed to do with those tiny things, glue them to a fingernail? Buy the world's tiniest wallet to keep them in?
I don't know about every computer having an SD card port, although I wish they did. The last laptop I had that had one built in was my ThinkPad X220.
In general though I do like portable storage gizmos, although I don't trust them and don't really have any need for them any more. I trust my hard drive in a German shed more (i.e. my cloud object storage gizmo).
RSS declined in prominence as social media rose. When “being social on the internet” revolved much more around blogging, RSS was a convenient way to subscribe to all your friends’ blogs and be notified when they had new posts available. The other main way was to maintain a blogroll – a list of links to your friends’ blogs, usually in your blog’s sidebar but sometimes on its own page – and individually click through and check every site just in case there was a new post available. Some web browsers would provide their own options, too; for example, Firefox used to have “live bookmarks”, which would notify you when that site had an update to its RSS feed.
MediaWiki extensions often follow a 'release branch' strategy of maintaining compatibility with MediaWiki core. This means that there's a Git branch in an extension that matches each core version. The idea is that development happens on the master branch, and every six months a release branch such as REL1_44 is created (based on master). Then, the only additional commits that happen on the release branch are for security or compatibility purposes, and are either applied directly or are cherry-picked from master.
I find two aspects of this a little bit annoying: Firstly, the speed of development of an extension is often much higher than that of core (as it should be; core shouldn't be a thing that's changing all that much). And secondly, it's not hard to introduce incompatibilities into the master branch of an extension. The latter seems to happen a bit, but is most annoying when a change adds some incompatibility, and then a subsequent change fixes it, but the normal way to backport these doesn't work because you have to add them separately and CI fails.
The trick is to add them as a merge commit. (Or at least, that's what I reckon… it doesn't seem to be a very popular approach, so maybe this is all Bad Advice.) It goes something like the following, assuming master has a few commits that are needed on REL1_44.
# First make sure everything's up to date, and switch to a new branch based on the release branch:
gitremoteupdate
gitcheckout-bupdate1-44gerrit/REL1_44
# Then create a merge commit with everything new from master:
gitmerge--no-ffgerrit/master
# Then upload the change for review, targeting the release branch:
gitreviewREL1_44
These encapsulated memories have become the last vestiges of an analog reality that is gradually becoming more diffuse. Physical photographs are now treasures of collective memory, and as such we have identified them in the work we do at Wikimedistas de Bolivia. We began two years ago by contacting the family of Bolivian designer Daisy Wende, and we expanded our scope with the Papeles y bytes libres program, through which we share images from the career of film and television director Marcos Loayza.
We are making slow progress managing new family archives. This work mainly consisted of mapping cultural actors whom we personally invited to donate archives from their personal records. Metaphorically and literally, we knocked on many doors. Thanks to these efforts, we contacted the family of musician and artist Alfredo Dominguez and found a lost image in Wikidata. We contacted the family of singer-songwriter Jesús Durán, to whom we owe some of the most emblematic cuecas in the national songbook, as well as the family of composer Alberto Villalpando, partner of writer and poet Blanca Wiethüchter.
My Commonmark LaTeX renderer is now listed on the list of community extensions to Commonmark. I figured I might as well make a 1.0.0 release today, it's been long enough. The last part that I had to do before that I actually did quite a while ago but only just merged today: adding 'smart quote' support, because LaTeX without that is very annoying. (I know that quotation mark direction isn't always deterministic, but it at least looks better now than never having opening quotes).
Interesting discussion about gathering information about user's wishes for Thunderbird development and how what people say can differ from how they actually use the system. Sounds very similar to working on MediaWiki!
The 60th Royal WA Historical Society State History Conference (archive link; see also the event page and its archive) was held in early September 2025 at the southern end of Lake Coogee in Henderson. It was the first time I've been to one of these conferences, and it was really worth going.
It was two and a bit days of talks, hallway track, food, insufficient coffee, and wet and windy weather. Some more organised delegates (not me) managed to go on tours of Azelia Ley Museum and Manning Park, Bibra Lake Wetlands, the Coogee coastline, and Woodman Point Quarantine Station. The last I really wanted to go on but it was all booked out.
Friday evening
The Friday night welcome event was at Hamilton Hill Memorial Hall, which is celebrating its 100th anniversary this year. I turned up a bit early, but there was an exhibition to look through, called "Wisdom Keepers", with eleven portraits of Cockburn locals accompanied by short histories of their lives in the area. A fair few market gardeners (and a bunch of other occupations too). I chatted with Allan Seymour, a photographer who's documenting "the old faces" (not the ones in the exhibition, that was Nic Duncan, with writing by Megan Anderson). Also with Mary Blight about white settler history and how we should be dealing with 19th century letters and things.
Rev. Mitchell Garlett gave the Welcome to Country, and talked for quite a while about his father Rev. Sealin Garlett (from Bruce Rock). It was interesting hearing him talk about learning hist family's history from his grandmother. It made me glad that I'd listened to at least a bit of what my own grandmother told me of our history. Mitchell lives in the house he grew up in and leads the church his father used to be minister of.
Saturday
A sideways map of Cockburn in the 1940s.
It was a humid and warm start to the day, and I tried to take some photos for Commons while waiting for the bus. I mostly failed in that, but got to the venue (the AMC Jakovich Function Centre, which I guess is mostly a shipbuilding sort of a place) nice and early and with time for coffee and meeting random history nerds from all over the state. Mostly the Perth Hills to start with, with various exciting news about new sheds and machinery restoration grants. But also closer to home, with a few Fremantle History Soceity members there.
The Welcome to Country was interesting, with a bit of an explanation about how "kaya" is the Noogar word for "yes" rather than "hello" as it's generally used these days. It was also the first listening we got to the rather crappy PA system, which throughout the weekend was crackling with static and clipping the speech. Fairly annoyingly.
Simone McGurk spoke about being a history nerd at high school and hiding out at lunchtime working on school history stuff. I very much relate (although for me it was building the school's history website that got me into the computer lab).
There was what seems to be a fixture of a "roll call" of each affiliated society, where everyone stood up as the name of their local society was called. Much clapping. And a bit of a sad presentation of the names of all members who have died in the last year (including my cousin Ian Berryman).
There were four main talks of the day:
Mary Blight on Midgegooroo (with a remote co-presenter who was introduced incorrectly and isn't listed in the programme, so I don't know who he was).
A panel of three of Jeanette Paulik, Rina Lovretta, Marica Blagaich, and Lorraine Gauce (and unfortunately I don't know which three because again the programme appears confused). They were talking with Bruce Baskerville about their lives growing up and living on market gardens in Spearwood. Really interesting, and gave me such a feeling of being glad to live in this part of the world.
Ross Anderson from the Maritume Museum with a very professional presentation about the shipwrecks in Cockburn Sound and other interesting underwater heritage (like the ex-slavery ship James Mathews, wrecked in 1841 off Woodman Point; and a de Havilland DH.100 Vampire aircraft that whose remains are somewhere in the Sound but are yet to be found.
The fourth session of the day was a social- and environmental-historical overview of the history of the Walliabup/Bibra Lake area, by Dr Nandi Chinna and Dr Catherine Baudins. Really interesting! A sad coverage of the intergenerational amnesia that we experience and how far the current bush is from what is was three generations ago.
Over morning tea it was wetlands mapping, more colonial diaries, and pretty good custard eclairs. The coffee was plentiful at that point, but by lunch had disappeared (I guess this wasn't a tech conference!).
After lunch, I didn't go on any of the tours so I thought I'd head off for a walk around Lake Coogee. However, five minutes after leaving the venue the rain came down, and ten minutes later I was soaked to the bone and waiting for a bus on Rockingham Road.
Sunday
In the hallway was a large exhibition with a huge number of text-rich information panels, and various cabinets of artifacts, and banners hanging from the railings. All about the history of community protests in Cockburn, from the Women's Action for Nuclear Disarmament in the 1980s to the Roe 8 protests more recently.
Sunday was much wetter and windier than Saturday, but being on the second storey looking out at the tuart trees (and almost the lake but not quite) blowing around and being dashed by the rain, was a fairly cosy way to spend the day. I nearly made it from the bus stop to the venue between showers, but didn't and so spent twenty minutes drying off in front of a fan.
The RWAHS (or "the royals" as everyone seems to call 'em) had their business meeting first up. Along with some information about the Federation of Australian Historical Societies (who "will list your society on the website for only $33/year"!). They royals are looking for more young people, and help with IT. I sat on my hands.
Someone mentioned the $12 billion that's being spent on Aukus and the new submarine base resources, but thought (rather grimly) that at least they might end up as "the heritage of the future", with "more submarines on the seabed".
The presentations were:
Maeve Harvey, with a terrific history of Coogee Beach and that area, such as Bernard McGrath's cottage on Coogee Lake. As well as the Noongar story of how that lake is saltier than the eastern chain of lakes because the sea had to rise up and flood it in order to put out a fire that was started when a bird stole the moon's fire. Every photo and figure in her slides was referenced to its source (not a common occurence).
Erik and Joshua Surjan, two brothers who grew up on market gardens in Spearwood, talking about their Croatian family, history, and wine making. Wonderfully, ending with a taste of their most recent vintage.
Dr Criena Fitzgerald told the story of the camel trade in Western Australia.
The life indeginous boxer and stockman Wandi Dixon (after whom the suburb is named), was detailed by Dr Michael O'Connor and Dr Denise Cook.
And lastly, Andrea Gaynor with an overview of the ecological conservation of Cockburn and why it's suceeding in many areas (at least compared to the fairly dreadful latter half of the 20th Century).
After lunch, people disappeared off on buses into the rain, to not go on walking tours of wherever they were going to. I nearly stayed put to work on some notes for Freopedia, but in the end there was enough of a break in the rain so I headed home.
I am heading to an OpenStreetMap mapping party in South Perth. Or at least trying to, currently sitting in an empty bus at Freo. The driver has gone AWOL.
The empty block next to Coles is seeing some action:
When photographing documents (in the slightly slap-dash but productive way we've been doing it at the Buffalo Club) it's necessary to set the camera's white balance to match the day's lighting conditions. With the Sony RX100 mk.V it's a matter of:
Set up the camera with the lighting conditions for the session, with nothing but a large white piece of paper in the frame. (Some paper has whitening chemicals added, which can throw things out, but that's a topic for another day.)
Use the Fn key to enter the menu, then go to the 'White balance' submenu.
At the bottom is the item, which enters the set mode. The white object only needs to fill the central area.
Click the centre of the control wheel to set the white balance:
Choose one of the three custom registers in which to save it:
The new values are saved and selected. To view them, you can go into the custom register, and view the values:
There are several services that offer image, audio, and video hosting, and some of them have free tiers. YouTube is a popular option for hosting vides, but I find ads and irrelevant recommendations so annoying that I've paid a few dollars for a bottom-tier Vimeo account. I don't do a lot of audio-only content, so no recommendations there. My biggest bandwidth hog is my image catalog. I explored using a content hosting service for them but wasn't interested in all the bells and whistles. I eventually settled on abusing GitHub as a hosting service. There seem to be no limitations on repository size, no throttling on bandwidth (at least at the scales I'm using it for) and I'm OK with the trade-off of free hosting in exchange for giving Microsoft unfettered access to my images.
It's the King's Birthday today. Not the King's birthday, mind — that will be on November 14 — but a day off in Western Australia. Not for me though! I'm working today, and having a day off later in the week instead.
The new system for managing the Wikimedia Community Wishlist should go live this week, which is a bit exciting. Hopefully it all goes well.
A couple of blog posts from my feed this week make me glad that there are companies around who are just interested in providing a good stable service that people want, without trying to stuff AI into every corner of it.
It’s all the rage right now. Everyone is scrambling to put AI into their products. The uncanny valley is shrinking enough that it’s hard to see how much AI was used to write something.
[…]
I stand by one of the most important truths about email. It’s not only the largest and most diverse social network, email is your electronic memory.
[…]
This is where the immutability of email really shines. An email is your copy, and the sender can’t revise it later. This is frustrating when you’ve sent the wrong thing and have to send a separate correction later, but in the long term it’s insanely valuable.
Discover how AI prompts replaced Git clone as the starting point for developers. Learn why prompt-driven development is reshaping how we build and deploy web apps.
Prompt-driven development is a new approach where projects begin with natural-language prompts instead of cloning repos. Developers describe their intent, and AI scaffolds functional code, moving the starting point from setup tasks to live project creation.
For over a decade, starting a new project began with opening GitHub, cloning a repo, and wrestling with setup before anything appeared on the screen. Today, many projects don’t begin with a repository at all. They begin with a sentence.
An evening walking around Freo. (Foolishly, I set my phone's aspect ratio to 'full', which of course doesn't mean full sensor but full screen, and so croppped the top and bottom of these.)
The Internet Archive has a new fundraising system. It sounds like quite a good idea for people who are using the IA as the digitisation store for archives hosted elsewhere. For most small archives, hosting the text portion of a catalogue should these days be almost free or at least very cheap. But hosting the images (and video and audio especially) is not, and the IA (and Wikimedia Commons, for PD material) is a pretty great place to put that. So this means you can use it in this way but also not feel like a total freeloader!
Peer-to-peer (P2P) fundraising allows donors to create their own page and garner donations in support of the Internet Archive. Every donation is tax-deductible, and 100% of all gifts raised directly support ongoing Internet Archive initiatives.
You have until December 31, 2025 to raise donations to help us reach a generous $1 million match—tripling all donations raised.
The P2P fundraising system is run by GoFundMe, but you end up on a page on donate.archive.org that asks you to sign up but doesn't say that it's actually signing up to GoFundMe — on the face of it, you'd think that clicking 'sign in' here would involve signing in to the IA.
Adding a $wgUnlinkedWikibaseEmulationMode feature on this sunny Sunday. Or maybe it should be called Immitation. Basically it can pretend to be Wikibase and expose the same Lua and wikitext API.
It seems that Dreamhost adds symlink directories called .dh-diag (and containing something like dh-php-diag.php which outputs something similar to phpinfo()). When I first saw one I thought perhaps it was a WordPress gone rogue and a dodgy script that'd been inserted — but nope, just some unexplained Dreamhost weirdness. Deleted, and things can go on their merry way (a Nextcloud upgrade in this case).
I noticed that a few new local streets had not yet been given names in OSM, so cycled up to have a look. Only the middle one, Friend Street, has a sign yet. I'm guessing the two lanes will get names at some point, so I'll keep checking.
I wonder if Friend Street is named after Mary Ann Friend?
So if you wanted people to read your blog, you had to make it compelling enough that they would visit it, directly, because they wanted to. And if they wanted to respond to you, they had to do it on their own blog, and link back. The effect of this was that there were few equivalents of the worst aspects of social media that broke through. If someone wanted to troll you, they’d have to do it on their own site and hope you took the bait because otherwise no one would see it.
I guess the issue is that these days if you write on your own site, no one will see it at all (while you'll still get a massive hosting bill because the stupid AI scrapers will hammer your site regardless). I don't particularly mind my words never being seen, I only keep a blog because I like to make notes for my own future reference, but it does lack the feedback systems that make social media enticing.
Today was Fremantle Studies Day 2025, this year's instalment of the annual day of talks put on by the FHS to launch the previous year's Fremantle Studies journal and for the authors of next year's to present their papers. It was held at the Army Museum, which is just up the road from me and so the damp weather didn't at all dissuade me from going. If anything, the drizzle just made Victoria Barracks a bit more atmospheric. Although, I had hoped to get some more photos than I did (because Commons hasn't very many, oddly for a military history topic).
It was a nice venue, the lecture room of the WA Army Museum, although acoustically perhaps not optimum (with stampeding of children on the wooden floors above and a weird re-verb that seemed to be enabled on the PA). Good food, and more importantly nice people to talk to. My main involvement with the History Society is to get their newsletters online, and now to get Fremantle Studies also uploaded to Freopedia. So I've got some homework to do.
The lecture room is also a gallery of honour boards, mostly WW1 I think. Only one that I saw is directly related to Fremantle, and I'll try to get its people listed on Freopedia soon.
There were meant to be four presentations, but due to the late change of venue one (Neil Stanbury) could not attend. This weekend's only uncontestedly re-elected councillor, Fedele Camarda, introduced the day.
At lunch I got chatting with one of the volunteer archivists of the Army Museum and she showed me around their library and archive. It's an impressive place. I shall try to book a time to go and research Frank Hussey, in case they have any Rottnest-related material.
Of the actual content of the presentations, I will post more later.
I've found the ruins of what seems to be a laundry fireplace, just to the south of the Barracks. The bricks come from the Cardup brickworks, which was started by George Lazenby (not the James Bond one).
An early start to a Monday, heading to Rottnest for a couple of nights. But it's a bright sunny morning, and although a bit windy it's from the east so shouldn't make for a rough crossing.
I got there, and went for a bit of a walk around, sitting in various shady places reading my book, and off to Padbury's Flat (I think it's called?) for a pre-lunch explore.
But hardly any photos, until I made it to the peculiar little room in the Barracks that I'd booked. I had my pick of fourteen wardrobes, and no table to sit at.
In the afternoon I did go for a walk along Gnank Yira Bidi, to the east.
UnlinkedWikibase is creeping closer to having a 'Wikibase imitation mode', in which Wikipedia (or whatever) templates can be imported and used without modification. There's a bit more to be done (making it work, for one, but also probably sorting out how the data is fetched and cached). The current progress is thanks to Naresh Kumar (aka User:TechieNK).
If you upload TIFF images to the Internet Archive,
it will produce JPEG versions of them (e.g.).
They'll be the same dimensions, but have a smaller file size.
Depending on the complexity of the image, and of course its size, the JPEGs might still be too big for use.
They are what gets used in the 'carousel' view that's shown when you open the item's details page,
which can be frustrating if there are a bunch of images and each one's JPEG version is a couple of megabytes.
TIFF derivative URL format: https://archive.org/download/<ID>/<TIFF base filename>.jpg
Not as frustrating, however, than if you upload PNG images (e.g.).
If you do that, IA doesn't create any derivative versions, and will happily try to display the full versions in the carousel.
This can make for a very slow browsing experience on the details page
if the PNGs are large (e.g. over 100 megabytes).
The best way to get reasonably-sized derivative images for display seems to be
to upload image Zip files.
These are created by first ensuring your image files (be they JPEG, TIFF, or PNG)
are named so that they appear in the correct order
and then zipping them up so they're in the top level of the zip file.
The file must then be given a name that ends in _images.zip, and uploaded to IA.
With these the carousel isn't used at all, but instead the bookreader is.
The bookreader shows smaller versions that, if you look at the requests your browser makes,
come from endpoints like https://ia801000.us.archive.org/BookReader/BookReaderImages.php.
This should not be used directly, because it's refering to a specific server;
the OpenLibrary book URL API exists for this purpose.
Zip derivative URL format: https://archive.org/download/<ID>/page/leaf<number>_w1000.jpg
The image zip process is easier than producing PDFs locally (e.g.) because many PDF creation processes will modify the embedded images in ways that are not helpful.
In about a week the kiddies lose access to some social media sites in Australia.
The idea that children should be shielded from the manipulation of the algorithms is a good one, I think.
To cope with (and maybe repel) the barrage of bollocks that rolls down the internet takes a more mature brain.
The fact that the politicians don't seem to care about how it'll actually be done doesn't really surprise me.
What will they do instead? When I was fifteen, I was typing HTML into SimpleText and uploading it to an iiNet web server.
My friends were doing the same, and we got to realise that we were all looking at each other's websites,
so we started embedding snide remarks about each other's design capabilities.
I remember being roundly teased for knowing how to link to a page, but not how "to link back again" to the first page.
So that's my recommendation to the yoof of today: get yourself a spot to chuck HTML, and go wild.
The people running the library seem not to see their institution as a library at all, in the sense of furthering the diffusion of knowledge or the nourishment of community. They see it as a cultural destination or an events space, the books and artefacts serving a largely scenic purpose. This would explain present trends, whose logical conclusion being a library without librarians – the perfect counterpoint to Yes Minister’s hospital without patients.
Today is Gunzel Day! So I feel like I should go on the train somwhere. Or at least observe some rail related activity, umarell-like. But I think the closest I might get is to head down to the basement and replace the brake pads on my bike.
A flow battery is, fundamentally, a machine. It has moving parts, and it potentially requires maintenance. Readers will have realised by now that I am quite mad rather obsessed somewhat of an enthusiast and don’t mind having to tinker with things occasionally. I imagine this is not the case for most people, who likely want their energy systems to Just WorkTM and require no special attention.
A viable flow battery, especially for residential usage, thus needs to be as low-maintenance as possible, and as easy to work on as possible when it does require maintenance. That latter point is a function of both unit design, and choice of installation site. The crawl space under our house for example is ideal if a battery only requires infrequent maintenance and minimal disassembly. If the whole unit needed to be stripped it would be much better off in a shed or other room that has appropriate access. Finally, these things need to come with a complete service manual including descriptions of all the parts and every possible procedure that might need to be performed in case of failure.
The City of Fremantle's new 3D mapping tool is pretty interesting. It shows current developments in green. Like the new St Pat's building that's currently being built, which is to be rather a lot bigger than I'd thought:
The building structures are super detailed for the most part. Of course, not available for re-use in OSM, sadly.
The Digitisation Centre of Western Australia DCWA was established with the goal of digitising collections of national and international significance held by organisations around the state.
This Symposium aims to continue to develop and enhance research synergies and opportunities in relation to the important cultural materials that have been digitised by the Centre to date. We warmly welcome interested researchers from across WA to participate in this important dialogue and look forward to a day of discussion and collegiality.
The future is (again) ending, with next week being the last ever episode of the Radio National programme Future Tense. I've had it in my podcast list for the last decade or so. But I can only assume they'll replace it with some sort of techy show. Antony Funnell is going to present Rear Vision. I guess the past (or at least non-future) is more fun these days. :-(
The thing about taking photos of plaques is that they often contain info that you don't read properly until later when processing the pics. Like the other day when I noticed that the old FTI screen had a plaque, but I assumed that the cinema geeks (of which there seem to be quite a few) would've got a photo of the actual structure. They hadn't though.
It's an old article, but for some reason my bespoke backlog randomisation algorithm brought it back to me this morning. The algorithm knows nothing of content, so the timing is just luck.
Imagine, if you will, wanting to go to a party. Imagine knowing that you will have a good time – that the mere experience of being around people fills you, as a matter of course, with joy and contentment. That you go home with a spring in your step, a song in your heart, a smile on your lips – refreshed, restored, rejuvenated and ready for the next one.
That is what life is like for most of the population. And then there’s us. The introverts. The people who do not need people. The people for whom people, en masse, are the worst thing imaginable. A stranger is not “just a friend you haven’t met yet”. This is a sentence that makes no sense to us. A stranger is just a person keeping us in a room, a situation we don’t want to be in, probably with music playing and definitely away from our books and our own lavatory.
The important thing about the open social web is not which protocol “wins.” It’s whether we build an ecosystem where publishers keep control of their distribution and readers keep control of their attention. RSS remains one of the strongest tools we have to make that possible.
RSS has always worked quietly in the background. In a moment when the web is being reshaped by enclosure, consolidation, and algorithmic mediation, its reliability is exactly what we need. It offers a simple, durable way for publishers to keep control of their distribution and for readers to keep control of their attention, without permission, platform lock-in, or hidden agendas.
People say we shouldn't try to smush every feature possible into MediaWiki. That when we get to the point of integrating an email client (or some chat system, I guess, to modernise the cliche) then we'll have Gone Too Far. Not to mention that perhaps some people don't see a future for MediaWiki outside the Wikimedia movement (which I don't agree with at all).
But I don't know. I do still think that there's great power in the everything's-a-page model. It's what all the cool kids do with Obsidian or static Markdown-derived websites, and a wiki is just like that but packed up and run in one place—and old and uncool.
So I'll persist, I think, in adding things I want to MediaWiki. Maybe not a mail client, but definitely something to do with indieweb tools, possibly webmentions. But maybe a mail client.
I seem to have started this hot Sunday with a bit of a revisit to Piwigo,
releasing a new version of the Flickr2Piwigo plugin.
Or rather, two new versions, because in the first one, 1.5.7,
I forgot that the vendor/ directory had to be included and so the GitHub integration of the release system couldn't be used.
So I promptly released 1.5.8 with vendor/
and with an actually updated version number in the code.
Clumsy, but it's been ages since I did a release there!
I updated Flickr2Piwigo today, or a few times in the last 24 hours actually, and dropped support for older versions of PHP. I usually bump the major version when a platform version is dropped, because it requires the person using the package to do something. Doing that seems to be a slightly contentious issue though.
A boat was being rescued in the harbour today, from being blown against the north wharf. Nothing terribly dramatic. Dareen (IMO 9074913) is the livestock ship behind. Oh and there's Leeuwin (still being rigged).
Tech companies are making decisions on our behalf about what our photos, and therefore our lives, look like.
We’re used to being lied to, and for new technologies to encourage an increasingly smoothed and yassified reality.
The above article makes some good points, but it does sort of muddle the different types of processing that come from old-school colour filtering and whatnot with the modern gen-AI approach. The former applies various, sometimes very complicated and clever, changes to a photograph that all work with the existing photo's data. Adding generative AI features on the other hand is about adding data to a photo that never had those pixels before. So clouds will look much more like clouds, and the texture of rivers more like what we see in the best nature photography, and these things make us feel like the phone is doing a good job of capturing the scene.
I'm not arguing for people to avoid these features. But I do think people should be aware of what they're capturing and what the software vendors are enabling by default. And at the very least, save the 'original' shots (and I know that doesn't mean-as-comes-from-the-sensor) and apply further processing to separate files. (Then again, it seems that many people these days have forgotten that photos are individual files anyway… but if I get on to that topic I'll be even more of a solidified scrooge, so I won't, not today….)
The Llangollen Canal had a bit of a failure the other day. I read somewhere (and annoyingly can't find it now) that there was a hurry to drop the barge boards into place up and down stream, to stop the canal completely emptying between locks. On one side the lock is quite close (it's somewhere around this location but the BBC doesn't like making maps). OpenStreetMappers are pondering how to map these places of stoppage, whether barrier=stoplogs is good. So, are they stop logs or barge boards or something else? (I could just look it up of course, but I thought I'd just put words out into the void of the old internet instead.)

_OpenStreetMap.png)














































 Firstly this cor-ten obelisk thing.
Firstly this cor-ten obelisk thing. "
" And the seafood factory near it, with it's large flow of water.
And the seafood factory near it, with it's large flow of water. The entrance to what was Quest Apartments, but which now has the sillily-punctuated name of "Be. Fremantle".
The entrance to what was Quest Apartments, but which now has the sillily-punctuated name of "Be. Fremantle". And the cruising yacht club's 'club house' (such as it is; more masts and less pomposity than the nearby Royal Perth Annex I think).
And the cruising yacht club's 'club house' (such as it is; more masts and less pomposity than the nearby Royal Perth Annex I think).






 Leaving the coast of Yemen
Leaving the coast of Yemen
 Arriving over Somalia
Arriving over Somalia

 Bosaso
Bosaso

 Quarries not far from Nairobi
Quarries not far from Nairobi
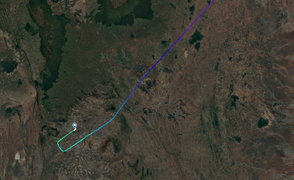
 Landing in Nairobi
Landing in Nairobi



















_OpenStreetMap.png)




_(2846280)_OpenHistoricalMap.png)








_Radar_Loop.png)











 Coles
Coles Target
Target





























 Sign to the Sea Rescue building (i.e. Fremantle Signal Station).
Sign to the Sea Rescue building (i.e. Fremantle Signal Station). Small trees growing in limestone.
Small trees growing in limestone. The lookout.
The lookout.


 The prominent pipe on the upstream side of the bridge has nearly been completely removed now.
The prominent pipe on the upstream side of the bridge has nearly been completely removed now.








 1912
1912 1935
1935.png)
.png)















































 Detail of the painting technique
Detail of the painting technique The original photo
The original photo

.png)

 The original photo
The original photo
.png)


 The original photo
The original photo



 The exhibition's web page.
The exhibition's web page.

 J Dolan Park
J Dolan Park "
" East Street Jetty
East Street Jetty "
" Port Beach
Port Beach Old CCS warehouse
Old CCS warehouse
























































 The rain passed just in time
The rain passed just in time
 It is there, just very far away!
It is there, just very far away!


 We quickly ran around to Vic Quay, to see them arriving
We quickly ran around to Vic Quay, to see them arriving












.jpg)


 Everything's Buffalo.
Everything's Buffalo.
 Edwin Workman, 1931
Edwin Workman, 1931.jpg)
.jpg)
.jpg)
.jpg)
.jpg)




















 Seemingly defunct olive grove on Gardiner Avenue.
Seemingly defunct olive grove on Gardiner Avenue.




 This is not where Henderson ends, according to the map.
This is not where Henderson ends, according to the map.















































.jpg)
.jpg)
.jpg)
.jpg)
.jpg)










 item, which enters the set mode. The white object only needs to fill the central area.
item, which enters the set mode. The white object only needs to fill the central area.




 Soon, all the old concrete pavers will be gone.
Soon, all the old concrete pavers will be gone.

 The cleaned-up corner site on Queen Street.
The cleaned-up corner site on Queen Street.






 Friend Street from the north…
Friend Street from the north… …and the south
…and the south Eastern lane from the north
Eastern lane from the north Western lane from the south
Western lane from the south












 Max Vickery
Max Vickery Leigh Straw
Leigh Straw Aurora Philpin
Aurora Philpin


.jpg)
.jpg)
.jpg)

























 High Street
High Street
 Point Street jacarandas
Point Street jacarandas CircusWA tent
CircusWA tent
 Bohemia Outdoor Cinema plaque
Bohemia Outdoor Cinema plaque
 Princess May wall
Princess May wall





























 Beach Street and the Australia Hotel.
Beach Street and the Australia Hotel. Captain Munchies site.
Captain Munchies site. Captain Munchies site, after being dug out for asbestos.
Captain Munchies site, after being dug out for asbestos. St Pats building site.
St Pats building site.






{kind=link}